
Gary Illyes, Standup Trends Analyst chez Google, @methode, a participé à une 2ème keynote sur le site de StoneTemple.com où Eric Enge l’a interviewé. A cette occasion, Gary revient sur le crawl de Googlebot, les tags SEO à utiliser et à quel moment afin de maîtriser son indexation et ce qui fait la qualité d’un site.
Découvrez la keynote de Gary Illyes :
La 1ère keynote est disponible sur YouTube.
TL;DR
Ce que nous apprend cette Keynote et qui moins souvent communiqué chez les SEO, c’est qu’il ne faut pas avoir peur de faire des backlinks depuis des gros sites de news et ce même vers des sources moins importantes, à partir du moment où cela renseigne l’utilisateur.
D’autre part, à plusieurs reprises Gary indique qu’il n’y a pas forcément un signal qui peut entrer en jeu mais tout un lot. Même si le référenceur a en tête qu’il y a plusieurs critères de positionnement, il oublie parfois d’élargir les horizons pour observer des effets de bord.
Gary ne donne pas la liste exhaustive des signaux influençant le robot de Google pour chacun des cas d’indexation qu’il aborde mais on retient que si le comportement de Googlebot n’est pas idéal, c’est qu’il faut investiguer davantage d’autres signaux de l’environnement. C’est notamment le cas pour une page dupliquée où c’est la mauvaise version qui est indexée. Il y a sans doute des signaux qui incitent Google à indexer cette version.
Voici le résumé en quelques mots des idées à retenir sur le crawl, l’indexation, les tags SEO et ce qui fait la qualité d’un site.
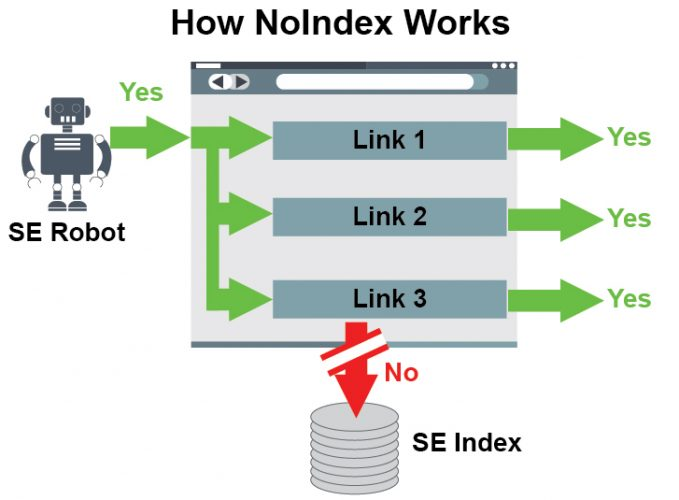
Noindex
- La fréquence de crawl sur une page noindex décroit dans le temps mais la vérification de la présence du noindex perdure tous les 2 mois puis 3 mois…
- Il y a un délai à prendre en compte après avoir apposé le Noindex : attendre un nouveau passage du bot.

Canonical
- Si une page ne doit plus être indexée, il est possible d’indiquer la page représentative qui la remplace avec un rel canonical : la plupart des signaux pertinents seront transmis La fréquence de crawl diminuera également avec le temps.
- Un grand retailer fait pointer ses facettes vers la home : mieux vaut créer une page catégorie pour cela.
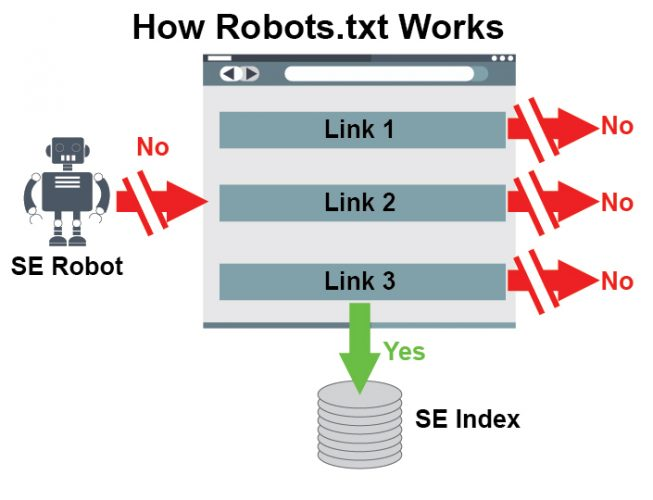
Robots.txt
- Google ne doit pas crawler la page : Google la crawlera si d’autres signaux le suggèrent mais la page ne pourra pas transmettre de signaux car on ne peut pas les connaître.
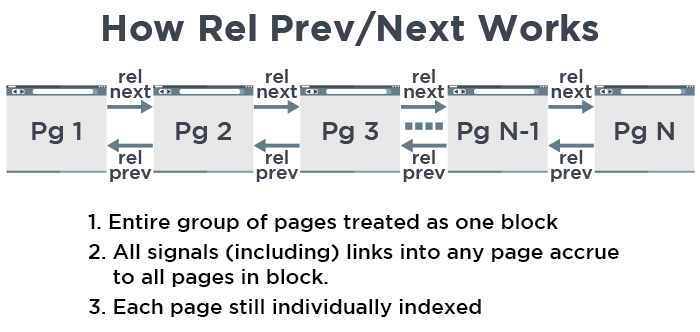
Pagination et rel prev/next
- Le lot de pages est considéré comme un seul bloc canonique, ce qui n’empêche pas Google de présenter autre chose que la page 1 si elle est plus précise pour un produit donné.
Hreflang
- Il est possible d’indiquer une langue seulement ou une langue et pays mais pas un pays seulement. Le marquage doit être 100% réciproque sinon si A lie B mais B ne fait pas de lien de retour alors B ne sera pas dans le cluster hreflang. Cela n’est valable que pour ce lien, si les autres liens sont ok ils seront pris en compte. Le nombre de liens réciproque est limité à la centaine (au delà c’est du spam).
Crawl budget
- Une notion chez Google s’appelle host-load (combien de chargement un site donné peut assumer sans devenir lent, ce n’est pas exprimé en nombre de pages. Cela ne détermine pas le crawl budget. Ce qui le détermine c’est l’importance des pages du site et non leur nombre. Une page du sitemap sera plus souvent crawlée sauf si c’est un sitemap généré automatiquement. Le PageRank est un des signals mais pas le seul.
- La page A propos de CNN qui change peu souvent est moins crawlée que la home qui change tous les jours et contient du contenu récent pour les utilisateurs.
- Si Google passe plus de temps sur les pages dupliquées ou interdites à l’indexation, il crawlera moins les autres pages qui pourraient s’indexer.
- La façon d’envisager le crawl peut évoluer en cas de site aussi gros qu’Amazon et encore Google a beaucoup de bande passante et d’espace disque.
Page e-commerce avec un filtre
- Une version sera par défaut et l’autre pointera en rel canonical vers la 1ère. Idem pour prix, couleur, taille…
- La rel canonical n’est pas une directive mais un signal parmi 12 pour la version canonique. La rel canonical n’est pas toujours respectée notamment si elle renvoie des erreurs (certificat HTTPs invalide).
Gestion des filtres en Ajax pour éliminer la création de nouvelles URL
- Cela fonctionne et Google prend en compte la page qui se charge par défaut en ignorant les autres pages
NoFollow
- Le Nofollow ne passe pas de signal par le lien. Ces autres signaux ne sont pas redistribués. Il n’est jamais la solution pour le linking interne, on lui préférera le rel canonical et le Noindex Une page à ne pas indexer doit voir son nombre de signal baisser et donc le nombre de liens avec ancre également.
UGC : User Generated Content
- Les commentaires de bonne qualité peuvent être modérés et indexables s’ils sont de qualité pendant que d’autres sont stockés dans un répertoire bloqué par robots.txt.
- Exemple de site avec UGC convenable pour Google : Stack Overflow
- How-to-site : Lifehacker en est un mais avec une communauté et bien construit donc c’est un site qui ne présente pas de risques.
Cas des très gros sites
- Les pages de faible contenu ne seront pas indexés pour ne pas perdre de ressource ni pour Google ni pour envoyer un mauvais trafic pouvant utiliser la ressource serveur du site à mauvais escient.
Indexation de pages dans des répertoires parents
- Sur la base d’URL example.com/vases/fleurs/orchidees, si les pages parentes de fleurs sont de hautes qualité alors le bénéfice du doute pourra être donné aux nouvelles pages découvertes sous cette section : vases/ sinon l’indexation se fera moins bien.
Sites de news qui ne font pas de backlinks par peur
Gary est en colère à propos des sites de news en général car ils ne réalisent plus de petits liens vers des publications plus petites ou des blogs car ils ont peur de faire des liens ce qu’il trouve stupide. Et ils leur en veut également car ils placent des NoFollow à tout bout de champ peu importe la raison. Il rappelle que l’Internet est bâti sur le principe des liens et cite l’exemple de ce site dans un article qui est mentionné à plusieurs reprises mais jamais lié. Le problème c’est qu’il existe deux sites du même nom : un au UK, l’autre aux U.S. Cela oblige à faire des recherches plutôt que de cliquer directement sur le bon lien
Supprimer un noindex
- Si on « noindexe » une page et qu’on enlève l’instruction quelques jours plus tard, on peut retrouver ses positions alors que si cela fait des semaines ou des mois, on repart du début.
AMP serait déployé à d’autres sites ?
Aujourd’hui seulement disponible pour les sites de news. Gary n’est pas certain des projets de Google à ce sujet, même s’il a entendu certaines choses qu’il doit confirmer avec ses supérieurs avant mais c’est une affaire à suivre.
On pense notamment à eBay qui n’est pas un site de news et qui a pourtant déployé AMP.
