
L’intelligence artificielle revient en force notamment depuis l’avènement des big data et l’amélioration des processeurs pour les calculs. Depuis 2006, de nouvelles technologies d’apprentissage automatique ont fait leur apparition. Côté moteurs, saviez-vous que le Machine Learning était déjà utilisé dans les années 2000 par Altavista pour classer ses résultats ? En 2015, Google RankBrain utilise le Machine Learning pour étendre la requête tapée par l’utilisateur. Les référenceurs découvrent RankBrain et entendent parler de Deep Learning.
Que sont tous ces termes scientifiques qui gravitent autour du Deep Learning ? Comment cet apprentissage profond permet d’utiliser des machines pour prédire les données ? En réalité ces technologies font déjà partie de notre quotidien.
- 1. Qu’est-ce que le Deep Learning ?
- 2. Qu’est-ce que le Traitement Automatique du Langage Naturel (TALN) ?
- 3. Deep Learning : Tout repose sur le réseau de neurones
- 4. Qu’est-ce que le Machine Learning ?
- 5. Comment Google exploite-t-il le Machine Learning ?
- 6. Le Machine Learning et les SERP
- 7. Google Deep Dream : le Machine Learning et les images
- 8. Applications Google combinant TALN et Deep Learning
- 9. Comment Google communique sur son utilisation du TALN et Deep Learning ?
- 10. Qu’est-ce que RankBrain ?
- Conclusion
Edit 02/06/16 : mise à jour de la prédiction du taux de clics sur les annonces.
1. Qu’est-ce que le Deep Learning ?
Le Deep Learning consiste ni plus ni moins à tenter de reproduire le comportement du cerveau humain.
Le Deep Learning est une des approches du Machine Learning parmi d’autres algorithmes tels les réseaux de neurones, les arbres de décision, les méthodes statistiques, la régression logistique, l’analyse discriminante linéaire, etc.
Google emploie le Machine Learning tel un nouveau concept mais c’est une technologie déjà utilisée depuis longtemps. Il s’agit de programmer des machines pour qu’elles apprennent d’elles-mêmes.
Le Deep Learning a permis des progrès importants et rapides dans les domaines de l’analyse du signal sonore ou visuel et notamment de la reconnaissance faciale, de la reconnaissance vocale, de la vision par ordinateur, du traitement automatisé du langage (TALN).
Oui, le Deep Learning c’est ça.
2. Qu’est-ce que le Traitement Automatique du Langage Naturel (TALN) ?
2.1 Définition
C’est l’ensemble des recherches et développement visant à modéliser et reproduire, avec des machines, la capacité humaine à produire et à comprendre des énoncés linguistiques pour communiquer (source F. Yvon)
2.2. Quelles sont les applications TALN qui existent ?
Le TALN concerne la production de texte, le traitement de la parole ou l’extraction d’information.
Cela correspond par exemple à la traduction automatique, le correcteur orthographique et grammatical, la reconnaissance de caractères (OCR) ou vocale et la synthèse de la parole sont autant d’applications issues du Traitement Automatique du Langage Naturel. Mais le meilleur exemple reste la recherche d’informations via les moteurs de recherche.
Le TALN est une discipline à laquelle on greffe une Intelligence Artificielle (IA) et qui mêle linguistique et informatique.
Le Deep Learning permet donc de le faire évoluer considérablement.
2.3 Jean Véronis, un expert TALN français
Parmi les premiers en France à s’intéresser à l’analyse sémantique, on pense au regretté Jean Véronis, professeur de linguistique et d’informatique, disparu en 2013.
En 2005, il constatait que Google gonflait artificiellement le nombre de résultats affichés pour des raisons marketing : « l’index véritable de Google est considérablement plus petit que la taille officiellement annoncée« .
Classé parmi 15 blogueurs leaders d’opinion sur la toile en 2006 par Le Monde, entre Tristan Nitot et Loïc Le Meur, Jean Véronis utilisait des outils d’analyse de statistiques pour mieux comprendre le langage naturel.
Cet ancien conseiller de Wikio (classement des tops articles) a également été observateur des discours politiques ce qui lui a permis de publier avec le linguiste Jean Calvet une analyse des mots de la victoire employés par un ancien président :

On lui doit une des premières tentatives de développer les sujets qui font le buzz via Twitter : Trendsboard
Voici un podcast de Jean Véronis où il explique qu’est-ce qu’est le traitement automatique des langues :
Il prédit que l’homme pourrait disposer d’un ordinateur dialoguant et lisant sur les lèvres des hommes comme le faisait HAL l’ordinateur dans 2001, L’Odyssée De L’Espace.

« Je ne le verrai pas de mon vivant », affirme-t-il dans le podcast ci-dessus. Il rappelle aussi qu’en 1946, on se donnait 5 ans pour pouvoir remplacer les humains par des traducteurs automatiques…
Un autre aspect intéressant du TALN sont les big data. Il s’y est également intéressé en les couplant aux technologies du langage :
« Ceux qui ont les datas sont Google, Microsoft, Facebook, Twitter, Amazon »
Il faisait également parti d’une association (Atala) dont la 23ème conférence sur le TALN est programmée pour les 4-8 juillet 2016
2.4. Une application pour le voyage exploitant TALN
Ainsi, le 12 mai 2016, une application a été lancée. Paul English (cofondateur du comparateur Kayak), a créé une app de voyage iOS appelée Lola : une sorte d’Intelligence Artificielle Personal shopper pour le voyage.
L’application utilise le Traitement Automatique du Langage Naturel et transmet les besoins à une équipe d’agents de voyage.
L’objectif est clairement de pouvoir traiter davantage de voyages par heure.
3. Deep Learning : Tout repose sur le réseau de neurones
Tentons de simplifier le concept au maximum.
3.1. Qu’est-ce qu’un réseau de neurones ?
C’est un réseau de neurones artificiels qui imite le fonctionnement du cerveau. En entraînant le réseau puis en l’appliquant, il est possible d’obtenir des prédictions.
En général, un réseau de neurones est organisé en réseaux de multiples couches afin de lancer des vagues de traitement dans un ordre précis. Cela permet notamment de classer de nombreux éléments en catégories, sans indiquer de critères.
3.2. Qu’est-ce qu’un réseau de neurones convolutifs ?
Un réseau de neurones convolutifs (CNN) est une méthode d’apprentissage automatique (Deep Learning) pour reconnaître des images.
Par exemple Google utilise ce système pour son service Street View afin de reconnaître les bâtiments puis d’essayer de déchiffrer les séquences de caractères affichées sur leur façade. L’objectif est de prédire la prochaine séquence.
4. Qu’est-ce que le Machine Learning ?
C’est le buzzword pour désigner le Deep Learning.

4.1. Chez Facebook
Yann LeCun a rejoint les équipes en tant que spécialiste du Machine Learning. Un projet de référence en la matière est DeepFace, une application de reconnaissance de visages (97% de réussite). Plus récemment, on a parlé de la mise en avant du contenu de haute qualité dans le flux d’actualités.
En outre, Facebook a lancé Facebook M, son assistant personnel. Et il y a peu DeepText UI, déjà utilisé dans son outil de messagerie Messenger afin de mieux comprendre les conversations et les questions que se posent les utilisateurs (très utile pour la publicité ciblée…).
La création d’agent d’intelligence artificielle, c’est-à-dire une IA par utilisateur a été confirmée par Joaquin Candela, à la tête de l’Applied Machine Learning group.
4.2. Chez Google
C’est la technologie TensorFlow qui désigne le Machine Learning. Geoffrey Hinton a été embauché en tant que spécialiste du Deep Learning pour lequel Google a déposé un brevet en 2003.
On trouve également un assistant chez Google, Google Assistant Google Now mais en plus puissant. Ce bot sera capable d’analyser le contexte de la conversation. L’objectif est de concurrencer Alexa Amazon ou encore Siri d’Apple.
Google a aussi racheté la startup DeepMind. On y trouve un projet sur le Jeu de Go ou encore des jeux Atari 2600, mais aussi la manipulation et transformation spatiale des données.
4.3. Chez Microsoft
Microsoft s’intéresse aussi au Machine Learning depuis 2014, notamment pour son assistant pour Windows, Cortana.
Mais cela fait depuis 1992 que Microsoft travaille sur le Machine Learning. L’équipe alors en place se penchait alors sur des problématiques de reconnaissance vocale et de modélisation du langage.
On peut même utiliser Azure ML, la techno Microsoft, avec Google Spreadsheet.
Il existe un Framework Microsoft bot pour construire ses propres robots permettant de dialoguer de façon autonome que ce soit pour Skype, Slack ou encore Office 365 : https://dev.botframework.com
5. Comment Google exploite-t-il le Machine Learning ?
5.1. Les algorithmes de qualité du moteur
Pour ne citer que les plus connus, Google exploite le Machine Learning pour améliorer les algorithmes de contrôle de la qualité des pages de résultats de recherche (SERP en anglais) : Panda pour le contenu et Penguin pour les liens.
5.1.1. Machine Learning et Google Panda
Dès 2001, Peter Norvig, directeur R&D chez Google, déployait déjà l’apprentissage par arbre de décision. C’est une méthode pour prédire la valeur d’une caractéristique en observant les autres caractéristiques du système. On entraîne un arbre de décision avec un dataset, puis on le compare à d’autres pour classer les pages dans les SERP.
Si vous voulez en savoir plus sur les arbres de décisions et Google Panda, parcourez le passionnant article de Ninja Bonnie.
5.1.2. Machine Learning et Google Penguin
Ainsi, imaginons comment le Machine Learning peut aider à déterminer un lot de caractéristiques menant à considérer un lien comme mauvais. Dans les points à contrôler, on pense :
- aux liens externes en footer ou en sidebar
- à la proximité du texte « sponsorisé » (ou expressions similaires) ou d’une image avec ce mot
- au groupement avec d’autres liens non pertinents
- à une ancre non relative au contenu de la page
- à des liens externes dans la navigation
- aux liens qui ne donnent aucune indication aux utilisateurs comme quoi il s’agit de liens (non souligné)
- aux liens sitewide
- aux liens depuis des sites non pertinents (depuis un annuaire, depuis un pays où on ne vend pas, etc.)
- à trop de backlinks depuis le même domaine ou sur la même IP
- aux liens depuis des sites de mauvaises qualité (et n’obtenant pas de liens eux-mêmes)
- aux ancres de liens externes trop similaires
- etc.
5.2. Doit-on utiliser le Machine Learning pour le classement Google ?
Google indique en 2011 qu’il n’utiliserait pas à 100% le Machine Learning pour ses SERP car cela est trop dangereux de les confier à un tel système :
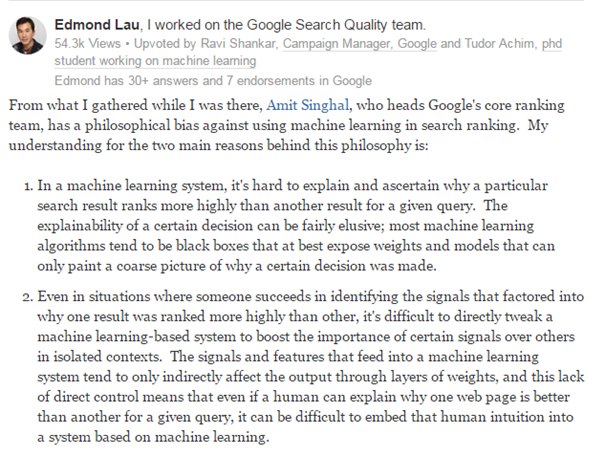
Cependant, Google l’utilise pour d’autres traitements automatisés, telle la prédiction du taux de clics sur les liens sponsorisés.
Prédiction des taux de clics sur les annonces
En effet, en 2012, Google a sorti un papier (attention langage scientifique inside) qui explique comment est utilisé le Machine Learning pour prédire le taux de clics sur les annonces : Les slides de Google sur la prédiction des taux de clics sur les annonces en 2013.
Prédire la probabilité d’un clic pour une annonce affichée en réponse à une requête donnée est l’objectif commun de tous les acteurs :
- 1. Les moteurs seront payés si l’utilisateur cliquent sur l’annonce
- 2. Donc les moteurs ne veulent que les annonces pertinentes
- 3. et les utilisateurs ne veulent que les annonces pertinentes
Le même travail de prédiction a été réalisé pour la prédiction du taux de clics sur les annonces Facebook et Criteo aussi a étudié le sujet, de même pour IBM :
Notons qu’il existe une API de Machine Learning pour faire vos prédictions comme Google.
6. Le Machine Learning et les SERP
6.1. De l’analyse du comportement humain dans les SERP
Google utilise déjà le Machine Learning pour analyser les logs de datas dont il dispose pour ses pages de résultats de recherche et ainsi prédire le comportement de l’utilisateur et son niveau de satisfaction lorsqu’il clique sur une page donnée.
L’algorithme peut alors distinguer des Long Clicks (satisfaction) des Short Clicks (retour aux SERP). Ce qui joue énormément dans la détermination d’un Google Panda. Sans compter le pogosticking qui consiste à revenir sur les résultats de recherche pour cliquer sur le résultat suivant. Cela envoie un mauvais signal à Google pour le premier résultat visité qui n’a pas donné satisfaction à l’utilisateur.
Source à propos des Long Clicks, des Short Clicks et du pogosticking
6.2. Le futur de l’algorithme de Google composé de 2 entités ?
Rand Fishkin, Moz, a récemment publié une présentation sur le Machine Learning :
Il émet notamment la prédiction que Google sera divisé en 2 principaux algorithmes : Google et les utilisateurs humains qui interagissent avec le contenu.
On peut imaginer des données utilisateurs injectées aux réseaux de neurones pour apprentissage sans indiquer de critères et la machine détermine quel sera le meilleur algorithme possible : « des algorithmes qui produisent des algorithmes (sans intervention humaine) ».
Une application au SEO pourrait être : « un résultat qui surperforme par rapport à d‘autres résultats eux aussi pertinents, le classe comme une réussite ».
L’utilisation du Machine Learning dans certains aspects du classement peut parfois expliquer, outre la communication, pourquoi les Googlers ne savent pas toujours pourquoi ou comment l’algorithme fait varier les SERP.
6.3. Et les Quality Raters dans tout ça ?
Les Quality Raters sont des personnes qui évaluent les SERP

Extrait de leur interface :
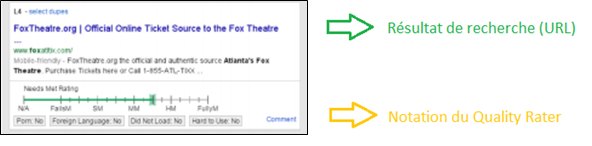
Google confirme que les évaluations des Quality Raters n’agissent pas directement dans les classements des pages.
Cependant, le principe semble similaire dans cet exemple de fonctionnement du Machine Learning ?
On y voit un sondage avec une question (l’URL à évaluer par le Quality Rater pour des SERP) et la réponse alimente la Machine pour qu’elle apprenne les notions de contraste (ou les notions de page de mauvaise qualité pour des SERP) :
Cela permettrait à Google d’influencer ses algorithmes sans agir directement sur les classements.
Cette théorie est notamment partagée par Sylvain Peyronnet comme l’indique le JDN.
6.4. De l’impact des clics sur les positions dans les SERP ?
Un test de clics dans les SERP réalisé par Moz en 2014 visait à faire classer une page plus haut. Le Googler, Gary Illyes avait alors confirmé que cela n’impactait pas le classement.
Mais la question reste entière si on teste plutôt l’impact des Long Clicks versus les Short Clicks.
Ainsi Rand Fishkin, Moz, se lance dans un nouveau test le 21 juin 2015 via Twitter afin de générer un Short Click sur le 1er résultat suivi d’un Long Click sur le résultat en position 4 :
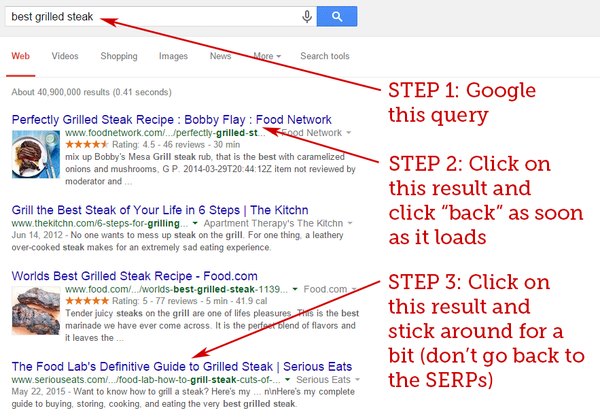
Le test a été concluant au bout de 2 semaines car le 1er résultat a été déclassé et le 4ème est passé en 1ère position. Ensuite au bout de 12h, la page promue est passée 13ème pour repasser 4ème au bout de 4h. Sans corrélation directe, on peut observer via Google Tendances de recherche que la requête « best grilled steak » a subi un pic ce jour-là.
Ainsi la page soupçonnée de manipuler les clics dans les SERP a été repérée voire pénalisée.
6.5. Quid du SEO avec le Machine Learning ?
Les anciennes techniques devraient évoluer avec l’avènement du Machine Learning.
Les critères impliqueraient davantage de CTR (taux de clics), d’engagement et de partages/liens ainsi qu’une intention utilisateur satisfaite et des visiteurs fidèles :
- Dépasser la moyenne du CTR pour une SERP donnée. (cf. Title, Meta tags, URL)
- Susciter l’engagement pour favoriser les Long Clics
- Répondre de manière exhaustive à l’intention utilisateur et à son but personnel
- Plus de partages et de liens et de fidélité (visiteurs réguliers)
7. Google Deep Dream : le Machine Learning et les images
En juillet 2015, Google a sorti DeepDream un outil open source qui permet de créer des visualisations en utilisant le réseau de neurones artificiel Deep Learning.
7.1. Comment marche DeepDream ?
Plusieurs millions d’images ont été ingurgitées par le réseau de neurones artificiels de Google pour apprendre à classifier les formes. Il est ainsi possible de reconnaître ces formes dans les images.
7.2. Comment est-il construit ?
DeepDream a été notamment conçue à partir du Framework Caffe basé sur le Deep Learning et d’autres librairies scientifiques dans le langage de programmation Python.
7.3. Comment utiliser moi-même DeepDream ?
7.4. Où tester la reconnaissance d’images avec ses propres images ?
Pour tester DeepDream en ligne, il existe ce générateur : deepdreamgenerator.com
N.B. : Comme la génération d’image avancée demande de la ressource afin d’utiliser plus profondément les réseaux de neurones, il faut s’inscrire pour obtenir des résultats de visualisations plus poussées. La génération pour chaque niveau de profondeur prend 15 à 60 secondes.
Partons de cette image originale : le mème de la petite fille à l’anorak jaune

L’algorithme n’essaie pas seulement de reconnaître ce qui est représenté dans cette photo. Le générateur accentue via différentes itérations (ici 6) les formes qu’il reconnaît. Ainsi on peut voir apparaître au fil des itérations de nouvelles formes.
Selon les itérations et l’image de départ, on peut aussi bien générer des images sans intérêt que des pures créations artistiques.
Exemple de reconnaissances de formes dans ce paysage de montagne, après 6 itérations (cliquez pour agrandir) :

De nouvelles formes animales sont venues peupler la montagne…
Finalement le concept, c’est un peu comme quand vous regardez les nuages et tentez d’y deviner des formes.
7.5. Utilisation de Deep Dream dans la musique
Des ingénieurs ont créé un logiciel, DeepUI, pour éditer les visualisations d’un clip musical (Years & Years, Desire mais la première vidéo utilisant DeepDream avait été créée par Calista & the Crashroots.
7.6. Coloriser des images en noir et blanc
DeepDream permet des fonctionnalités époustouflantes telle la colorisation de photos en noir et blanc.
Le projet http://richzhang.github.io/colorization/ fonctionne par l’usage de réseaux neuronaux convolutifs, un système de vision par ordinateur qui mime les visualisations bas niveau de nos cerveaux pour percevoir les motifs et catégoriser les objets :

Son concurrent : http://people.cs.uchicago.edu/~larsson/colorization/

8. Applications Google combinant TALN et Deep Learning
Google dispose de nombreuses applications telles la reconnaissance de la voix dans l’app Google ou encore Smart Reply dans Gmail et la recherche dans Google Photos. Découvrons quelques exemples déployés par Google.
8.1. Traduire une image avec Google
Une fonctionnalité développée par Google permet de prendre en photo un morceau de texte et d’en obtenir la traduction en temps réel : Traduire des images
8.2. Légender automatiquement une image
Pour légender de façon naturelle les images, un système combine à la fois le réseau de neurones au traitement automatique du langage naturel.
En savoir plus : http://www.abondance.com/actualites/20141120-14432-google-cree-automatiquement-descriptions-textuelles-dimages.html
8.3. Répondre automatiquement aux mails
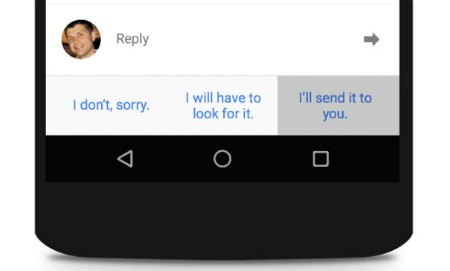
Smart reply de Gmail répond à vos mails pour vous
9. Comment Google communique sur son utilisation du TALN et Deep Learning ?
Google émet des publications en anglais sur le Natural Language Processing et cite les réseaux de neurones et même la résolution d’entités pour le Knowledge Graph :
Our syntactic systems predict part-of-speech tags for each word in a given sentence, as well as morphological features such as gender and number. They also label relationships between words, such as subject, object, modification, and others. We focus on efficient algorithms that leverage large amounts of unlabeled data, and recently have incorporated neural net technology.
On the semantic side, we identify entities in free text, label them with types (such as person, location, or organization), cluster mentions of those entities within and across documents (coreference resolution), and resolve the entities to the Knowledge Graph.
Mais aussi des communiqués pour la Presse

ou encore des publications plus scientifiques via le Blog Google Research
10. Qu’est-ce que RankBrain ?
RankBrain a été introduit par Google pour étendre la requête utilisateur.
Son nom indique bien qu’il mime les principes de fonctionnement du cerveau. Il est donc possible en y injectant des données que cela influence la requête ainsi étendue. On pense par exemple à l’historique de recherche ou la localisation de l’utilisateur.
On peut ainsi schématiser RankBrain ainsi dans la vue d’ensemble du Classement Google :
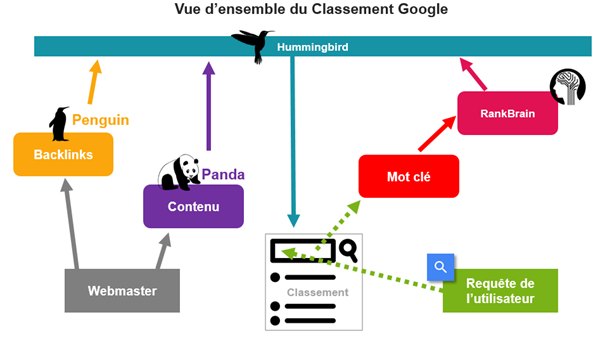
RankBrain est issu de TensorFlow https://www.tensorflow.org, un outil open-source développé par Google permettant l’apprentissage automatique.
En quoi cela peut servir le SEO ?
La création de pages de questions réponses dans un objectif de positionnement sur ce type de requêtes va grossir avec l’arrivée de la recherche vocale.
Conclusion
Microsoft, Facebook et Google emploient le Deep Learning dans leurs nouvelles interfaces vocales, et elles sont de plus en plus performantes.
IBM a quant à lui créé le système Watson qui répond aussi bien aux questions d’un jeu TV (Jeopardy) qu’à des applications dans la médecine, le marketing, etc.
Il faut suivre également de près l’apprentissage statistique. S’il date des années 90, il dispose d’algorithmes de classification performants pouvant exploiter des big data. Vous le connaissez déjà via les filtres anti-spam, le marketing digital, ou les moteurs de recommandation.
Google, quant à lui, s’oriente vers des projets toujours centrés sur l’assistance aux humains pour mieux « prédire » leur comportement et lance Google Home https://home.google.com. Un petit boitier installé chez vous reconnait votre voix pour lancer diverses applications pour la maison.
Malgré tout ce que nous savons du Machine Learning, tout ne peut pas encore être géré par les IA mais leur efficacité est grandissante.
Les GAFA l’ont bien compris :
Et vous que feriez-vous avec du Machine Learning ?
