
La célèbre encyclopédie en ligne est, dans le milieu du référencement naturel, un peu considérée comme étant le Saint Graal. Les positions de Wikipédia dans les résultats des moteurs de recherche sont bien souvent sans équivoque : en première page, si ce n’est en première place, et ce, sur la majorité des requêtes à un mot ou sur les noms propres. Ce seraient les requêtes les plus recherchées, les plus apporteuses de trafic qui sont ainsi occupées par l’encyclopédie gratuite et sans publicité.
Page d'accueil de fr.wikipedia.org
Après avoir tué les vendeurs d’encyclopédies qui faisaient du porte à porte, Wikipédia tuerait la possibilité pour un référenceur d’obtenir la première position ? C’est ce que semble confirmer un article paru dans le JDN, relayant l’étude du site britannique Intelligent Positioning. Nous allons voir pourquoi il faut relativiser.
Sommaire
Wikipédia et Google
Cette apparente domination est telle que les suspicions les plus folles existent, souvent contradictoires. Google favoriserait Wikipédia au détriment d’autres sites, parfois plus pertinents : ceux qui voudraient être devant Wikipédia n’auraient alors comme seul recours que de passer par les liens sponsorisés. N’oublions pas que Google a déjà fait des dons de plusieurs millions de dollars à la Wikimedia Foundation, l’entité qui gère Wikipédia! Ou alors, à l’inverse, Google ferait tout pour pénaliser Wikipédia : le site représente tout de même un manque à gagner colossal pour le monde de la pub en ligne dont Google est l’acteur majeur et incontournable. La vérité est sûrement ailleurs, comme disait quelqu’un du FBI il y a quelques années.
Il est vrai que cette domination écrasante a de quoi faire tiquer : première page Google sur 99% des requêtes ! Mais en regardant d’un peu plus près, de quelles requêtes parle-t-on ? L’étude a été menée exclusivement sur des requêtes composées d’un seul mot. Ce type de requête n’est plus majoritaire, les internautes tapant essentiellement des requêtes à plusieurs mots. Ceci relativise l’importance de Wikipédia dans les résultats des moteurs de recherche.
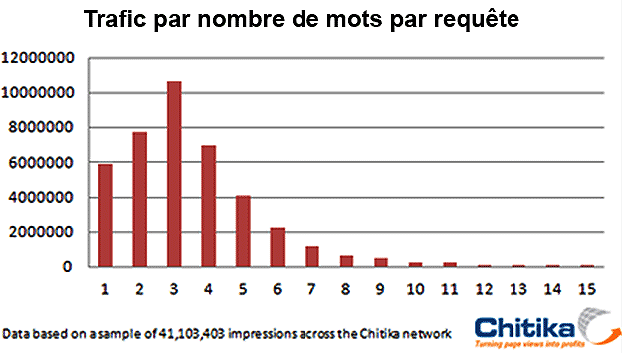
Etude du réseau Chitika, 2010
Google n’a pas véritablement d’algorithme pensé et prévu pour favoriser (ou pénaliser) Wikipédia en particulier. En revanche, les critères de positionnement de Google sont presque systématiquement positifs pour l’encyclopédie en ligne. Même si l’un des critères n’est pas aussi performant (peu de contenus par exemple), les autres critères peuvent rattraper largement cette lacune.
Critères de contenus
Les contenus de Wikipédia sont, comme on pouvait s’y attendre, encyclopédiques. Le site traite ainsi de façon exhaustive de la plupart des sujets. Ces sujets, rédigés par une armée de bénévoles et ce dans presque toutes les langues, sont constamment mis à jour. Tous sont structurés, avec un sommaire et des liens vers des sujets complémentaires.
Wikipédia est un gage pour l’internaute d’obtenir une réponse quasiment 100% du temps. N’oublions pas que Google regarde de plus près une requête, en essayant de comprendre ce que désire l’internaute, comme exposé dans notre article sur les critères d’évaluation de Google. Une requête à un mot clé est très souvent synonyme de la recherche de signification de ce mot, ce que Wikipédia fait mieux que les autres sites la plupart du temps.
Sur les mots où il est admis que la plupart des internautes savent et comprennent leur signification, et qui sont en outre concurrentiels, Wikipédia ne ressort plus si facilement. Tapez des mots comme « banque », « assurance » « bourse », « immobilier », « foot », « annonces », « mutuelle » ou « actualité » : où est Wikipédia ?
Critères de « confiance »
Le signe le plus évident de la confiance portée par les internautes à Wikipédia se retrouve dans les recherches de la marque. « Wikipédia » est ainsi une des requêtes les plus populaires de Google, démontrant à Google de l’importance du site aux yeux des internautes. Pour enfoncer le clou, une très grande part de requêtes sont associées directement à la requête Wikipédia, l’internaute explicitant clairement à Google qu’il veut un résultat provenant de l’encyclopédie en ligne, et pas un autre. Tapez par exemple « mutuelle », vous verrez qu’une des recherches associées n’est autre que « mutuelle wikipedia » !
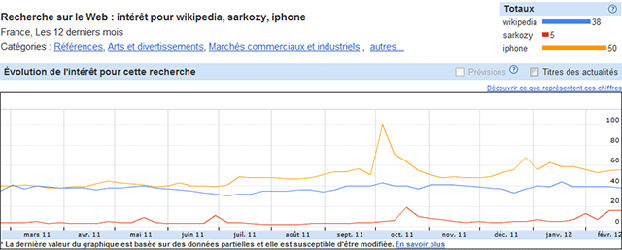
Recherche des mots clés « sarkozy », « iphone » et « wikipedia », Google Insights
Pour parfaire ses critères de confiance (pensons à leur brevet « Search Result Ranking Based On Trust »), Google mélange avec ces recherches de marque les signaux sociaux : ce sont les mentions sur Facebook, Twitter et autres réseaux de relais de réputation. Ici aussi, Wikipédia a une longueur d’avance sur le reste de la planète web : bon nombre de ses articles sont cités, repris, « likés » ou « retweetés » en masse.
Cette confiance se retrouve dans les 2 millions de visiteurs uniques quotidien, pour la seule France. En un mois, ce sont 55 millions de visiteurs uniques en France, et 1,2 milliards au monde, en faisant le 6ème site le plus visité en France (et ailleurs) selon Alexa, derrière Google, Facebook ou Youtube…
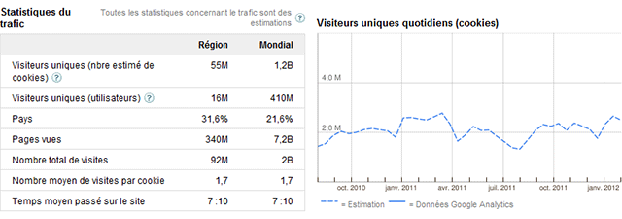
Trafic estimé de Wikipédia, Google Adplanner
Critères de PageRank et de liens externes
Les liens extérieurs au site pointant vers Wikipédia, l’un des plus anciens critères de positionnement de Google sont à la mesure du site culturel le plus populaire de la planète : innombrables, de toutes sortes, venant de très gros sites réputés ou de petits blogs obscurs. Rien que sur le mois de décembre 2011, plus de 200 000 sites différents ont fait un nouveau lien vers l’encyclopédie libre. Wikipédia présente une courbe de progression de ses nouveaux liens absolument idéale, représentant même « l’étalon » auquel on devrait comparer les autres sites. Le PageRank, l’ancienne marotte des référenceurs en herbe est lui aussi conséquent : PR9 sur la page d’accueil internationale, PR7 sur la page d’accueil française. La force du PageRank de Wikipédia n’est pourtant pas sur ses pages d’accueils, mais sur ses pages internes, très bien notées par Google. L’article dédié à la France a ainsi un PR7, celui dédié au sèche-linge un PR4…
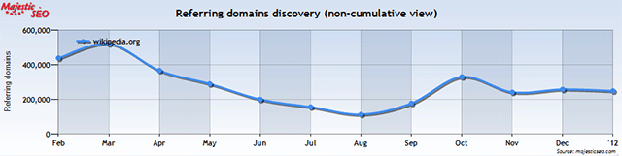
Evolution des nouveaux noms de domaines pointant vers wikipedia.org
On le comprend, le pouvoir de positionnement de Wikipédia dans les moteurs de recherche est tel qu’on peut obtenir facilement et sans effort une première position en créant un article sur l’encyclopédie, et ne pas arriver à se classer dans les 10 premiers avec rigoureusement le même article sur un autre site : la force du contenu n’est pas tout, et Wikipédia apporte une réponse globale à toutes les grandes difficultés du référencement naturel.
Analyse RESONEO
RESONEO utilise au quotidien son outil interne, Matriceo, permettant d’effectuer une veille permanente sur un nombre très conséquent de mots clés. Plusieurs millions de requêtes sont ainsi scrutées, que nous pouvons trier ensuite par type d’activité. L’étude de Intelligent Positioning ne porte que sur un petit échantillon de 1000 mots clés, relativisant encore plus la portée de leur étude…
Notre tableau générique est absolument sans appel : en janvier 2012, wikipedia.org était loin, loin devant le deuxième, Youtube.com sur Google.fr. Wikipédia était présent sur 2971575 mots clés étudiés par Matriceo, pratiquement le double de Youtube.
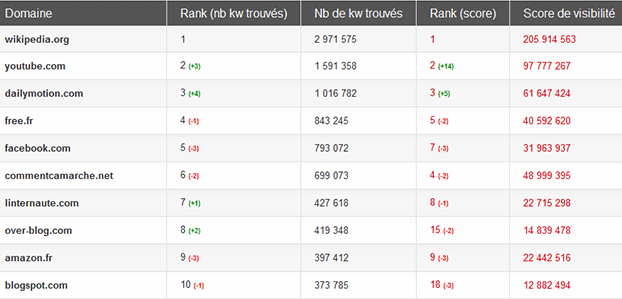
Top des sites en janvier 2012, Matriceo
Il existe pourtant encore des secteurs où Wikipédia n’est pas majoritaire, loin s’en faut.
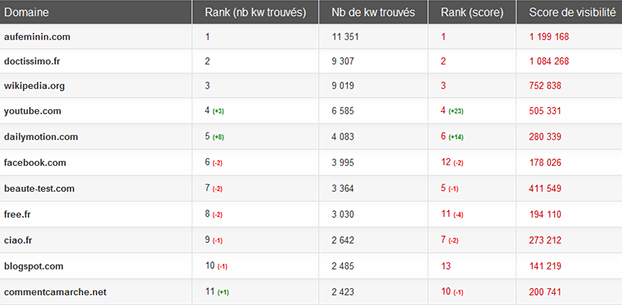
Top des sites « beauté » en janvier 2012, Matriceo
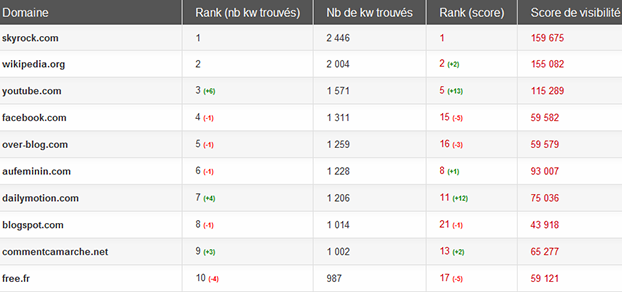
Top des sites « communauté » en janvier 2012, Matriceo
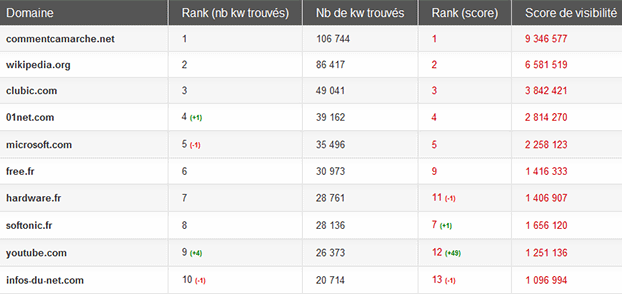
Top des sites « informatique » en janvier 2012, Matriceo
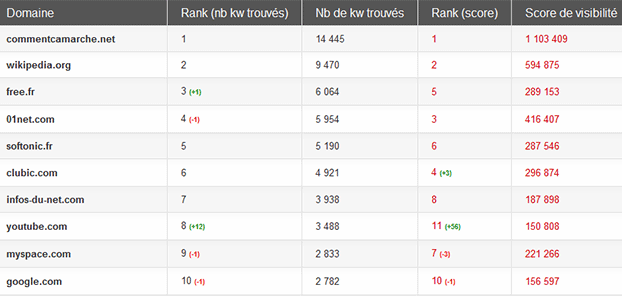
Top des sites « internet » en janvier 2012, Matriceo
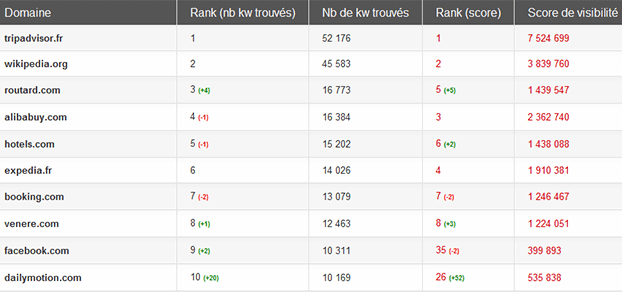
Top des sites « voyage » en janvier 2012, Matriceo
On le voit, la présence de Wikipédia connait de grandes variations suivant les secteurs. Ce que Matriceo nous indique en revanche, c’est l’amélioration progressive des résultats Wikipédia ! L’encyclopédie est de plus en plus présente sur les premières positions, comme on peut le voir sur notre étude, mesurant la progression du site depuis 2010.
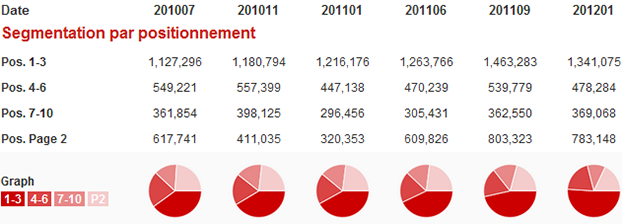
Positionnement de Wikipédia dans les résultats de Google.fr, de juillet 2010 à janvier 2012.
Cette progression s’explique bien sûr par l’enrichissement et la mise à jour permanents de l’encyclopédie en ligne, et une popularité croissante. Wikipédia est devenu la référence en matière de connaissances, le site couvrant la plupart des requêtes grâce à ses 1 216 764 articles en français au 23 février 2012.
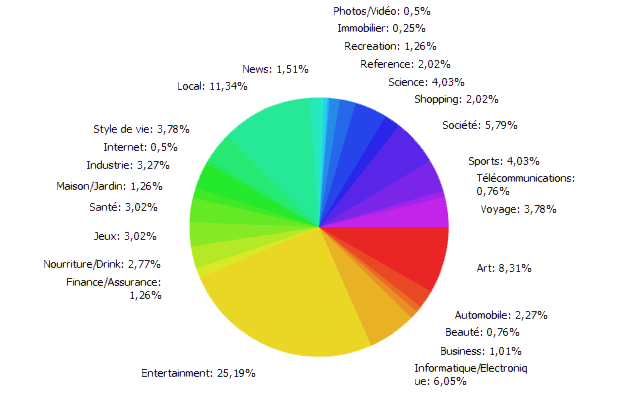
Répartition thématique de la présence de Wikipédia sur Google
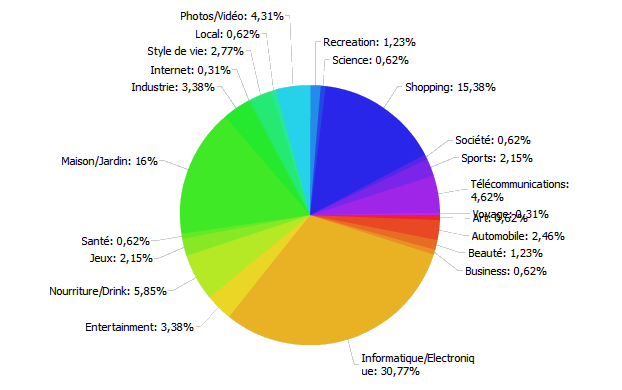
Répartition thématique de la présence de Rue du Commerce sur Google
En observant la présence de Wikipédia par familles de mots clés et en la comparant à un site marchand comme Rue du Commerce, il est aisé de constater une meilleure représentation pour Wikipédia sur des thématiques comme le divertissement, les Arts ou le sport. La force de Wikipédia, c’est sa présence sur toutes les thématiques possibles, abordant tous les sujets imaginables, ce qui démarque l’encyclopédie de tous les autres sites qui ne traitent que de quelques thématiques.
Wikipédia et le SEO
En tant que référenceur, le projet majeur de la Wikimedia Foundation est pratiquement intouchable. Le site est ce qu’on appelle un « trou noir » en référencement, recevant beaucoup de popularité venant de la multitude de liens externes, mais n’en redistribuant aucune, les liens sortants étant presque tous en « nofollow », pour « éviter le spam ». Ce net déséquilibre fausse d’avance le combat, Wikipédia n’ayant que faire de l’échange de liens, de la course à la popularité ou de l’obtention de nouvelles références. C’est un site qui se suffit à lui-même.
Google, contrairement à ce que l’on pourrait croire, ne favorise pas volontairement Wikipédia, bien au contraire. L’algorithme a bien souvent été raffiné pour varier les premières positions, jouant sur de nouveaux critères, afin de trouver la page la plus pertinente pour ces requêtes à un seul mot clé. Si vous tapez par exemple une région de France, vous trouverez probablement en première position le site de l’office du tourisme ou celui du Conseil régional : à bien y penser, quand vous tapez « Bretagne », vous cherchez à savoir que la région est peuplée depuis le paléolithique inférieur, ou plutôt ce qu’il y a à visiter dans cette belle région française ?
En résumé, le favoritisme apparent de Google pour Wikipédia n’est qu’une conséquence de son mode de calcul de positionnement. Pour bien référencer un site, Wikipédia est l’exemple même de ce qu’il faut faire : liens entrants externes, liens internes, contenus, popularité de marque, structure du code, vitesse d’affichage, tout est pris en compte et de très grande qualité.
Il existe bien des optimisations à faire, MediaWiki commençant à vieillir : le jour où ceci sera fait, Wikipédia sera encore plus redoutable, si c’était encore possible !
Pour finir, rappelons que les requêtes les plus concurrentielles, où il y a de l’argent en jeu, ne sont pas occupées (je devrais dire squattées) par Wikipédia. Le principal ennemi de l’e-commerce en référencement naturel n’est pas « l’encyclopédie libre », qui de toute façon ne vend rien et n’est donc pas un véritable concurrent, mais bien l’affichage de liens sponsorisés, qui prend ces derniers temps de plus en plus de place sur nos écrans…
